New Intent Detection: Identifying the unknown (novel) user intents that have never appeared in the training set is a challenging task in the dialogue system.
1. ACL-2019: Deep Unknown Intent Detection with Margin Loss.
优点:模型看起来较简单,缺点:只能检测unknown intent。可作为检测未知意图的一种简单方案。
推荐指数****。
code: https://github.com/thuiar/DeepUnkID
1.1 摘要
检测一个句子属于特定intent class还是属于unknown intent(group unknown intents into a single class)。其中unknown intent可能是out-of-intent,但训练过程不需要out-of-intent的数据。
1.2 方法:定位为分类问题。
第一阶段-extract deep features: BiLSTM + LMCL(Large Margin Cosine Loss) ;
第二阶段-detect unknown intents:LOF(Local Outlier Factor)。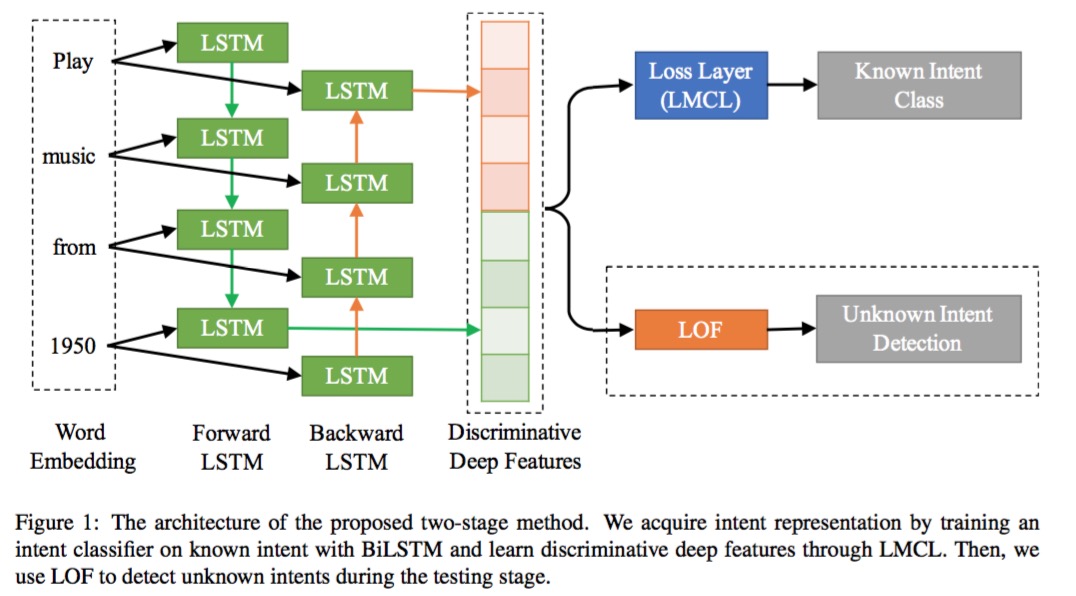
- LMCL(替换softmax)目的:最大化类间方差和最小化类内方差。通过对特征向量和权重向量进行L2归一化以消除径向变化,将softmax loss表示为cosine loss。在此基础上,引入余弦间隔(margin),进一步最大化角空间中的间距(角间距)。 提出时用于人脸识别。
- LOF(局部异常因子)目的:异常检测。通过计算一个数值score来反映一个样本的异常程度。这个数值的大致意思是:一个样本点周围的样本点所处位置的平均密度比上该样本点所在位置的密度。比值越大于1,则该点所在位置的密度越小于其周围样本所在位置的密度,这个点就越有可能是异常点。
1.3 实验
train选择部分类别作为unknown,test使用全部类别。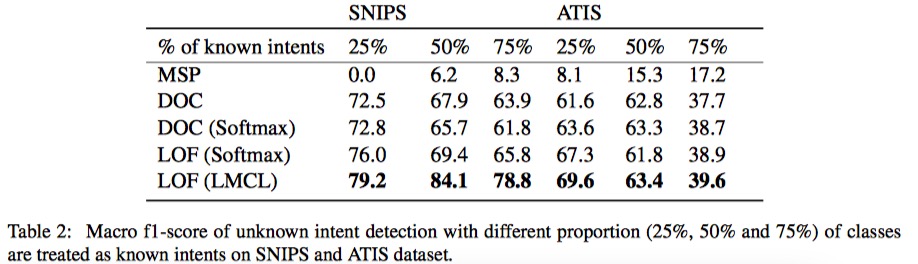
注:known intents比例越高,越不易判断是不是unknown。
1.4 主要参考文献
1)Feng Wang, Jian Cheng, Weiyang Liu, and Haijun Liu. 2018a. Additive margin softmax for face verification. IEEE Signal Processing Letters, 25(7):926–930.
code: https://github.com/happynear/AMSoftmax
2)Markus M Breunig, Hans-Peter Kriegel, Raymond T Ng,andJo ̈rgSander.2000.Lof:identifyingdensity based local outliers. In ACM sigmod record, volume 29, pages 93–104.
2. AAAI-2020(CADC-plus): Discovering New Intents via Constrained Deep Adaptive Clustering with Cluster Refinement.
优点:端到端的intent聚类方法,缺点:假设一个句子只有一个intent。
推荐指数*****。
与上篇同作者,code: https://github.com/thuiar/CDAC-plus
2.1 摘要:定位为聚类问题。
现有方法依赖复杂的特征工程,容易过拟合并且对cluster数目较敏感。本文提出一个端到端的intent聚类方法。题目的几个关键词,Constrained指利用少量的label data;Deep Adaptive Clusterin(DAC)指获取pairwise-classification作为先验知识;Cluster Refinement指利用KLD-loss refine the clusters,使得模型对cluster数目不敏感。
2.2 方法:假设每个句子只有一个intent,模型分为3段式,
step 1. 利用BERT获取intent representations;
step 2. 利用句子对是否相似构造 pairwise-classification任务;
step 3. Cluster Refinement with KLD loss。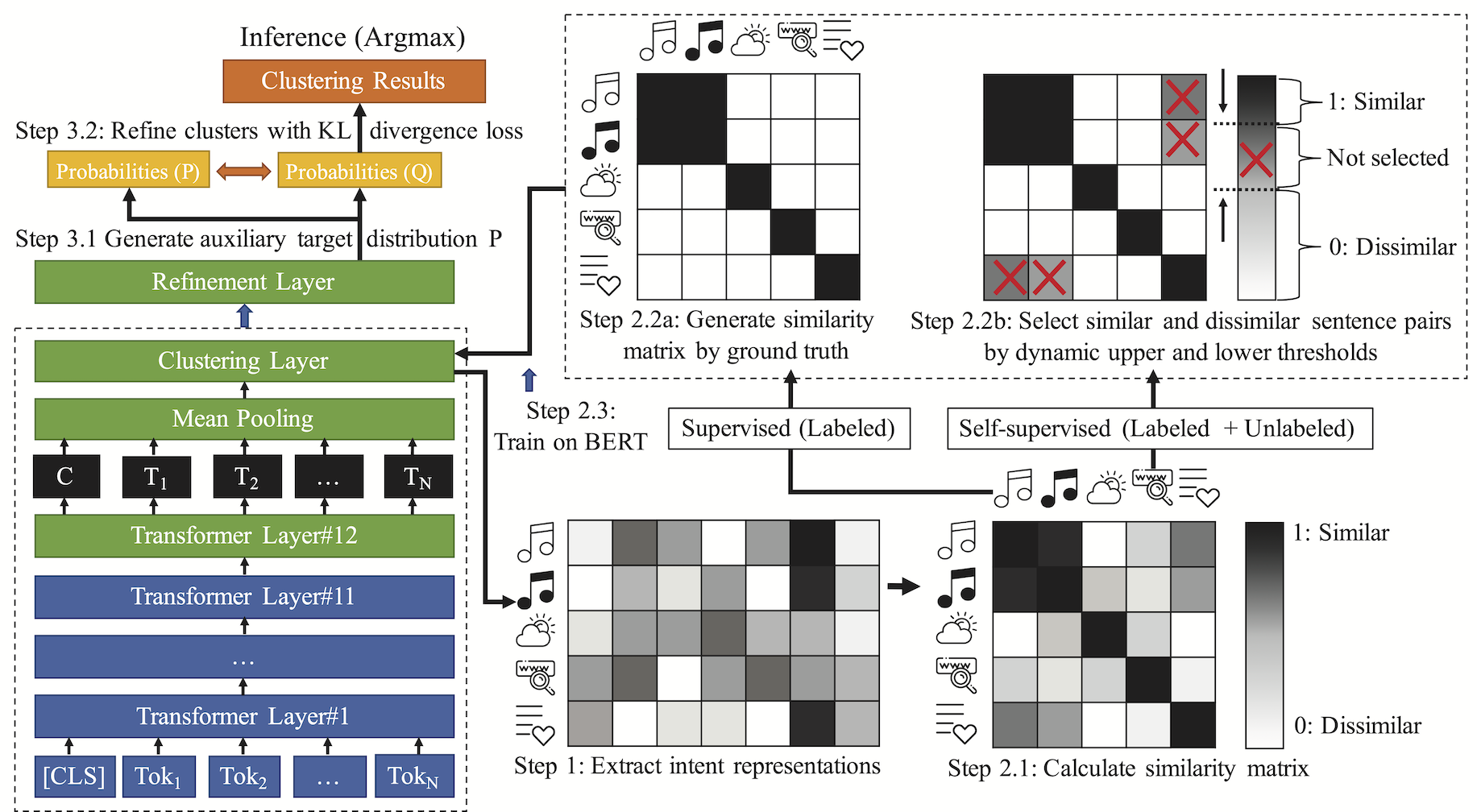
2.3 实验
train选择25%的类别作为unknown,10%的类别作为label data。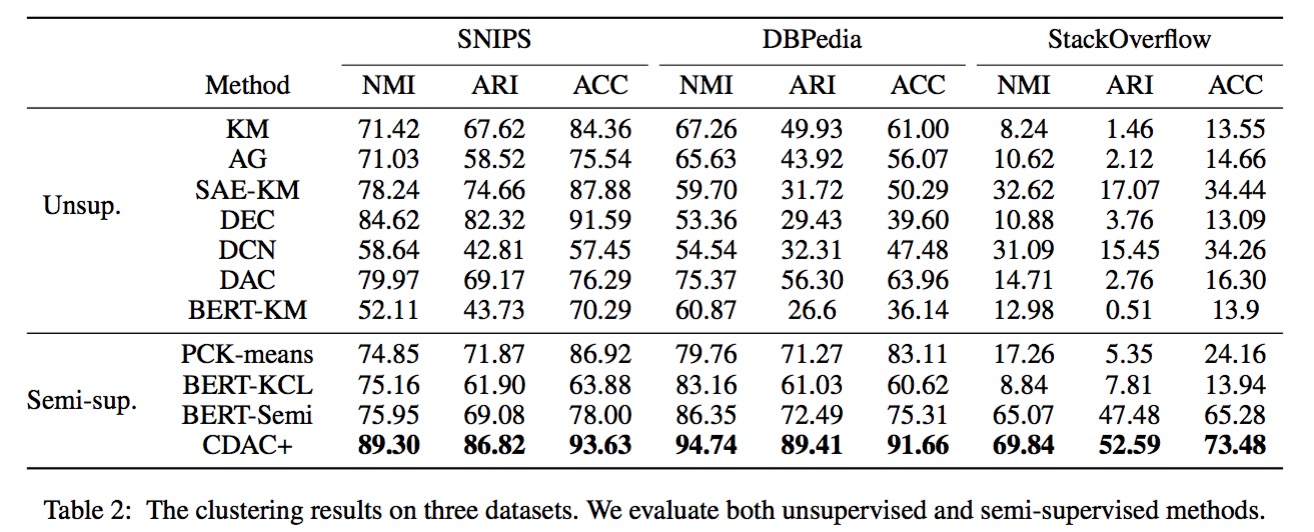
3. ACM-2019(TOP-ID): Towards Open Intent Discovery for Conversational Text.
优点:可挖掘比较细致的新意图,缺点:模型细节较复杂无源码。
推荐指数****。
3.1 摘要
将open intent discoverry看作sequence tagging problem。适用于异步对话系统发现新意图。
3.2 方法:定位为序列标注问题
Bi-LSTM + CRF + Mulit-Head Attention + Adversarial Training。 We consider three tags: Action, Object, and None (denotes all the remaining words or phrases in the text utterance that are neither an Action nor an Object), 主要分为2阶段:
step1: open intent existence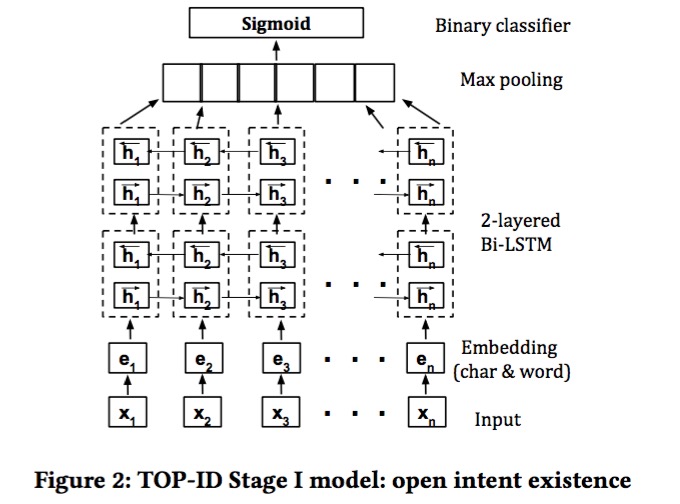
step2: open intent extraction
Bi-LSTM(adversarial training and attention) + CRF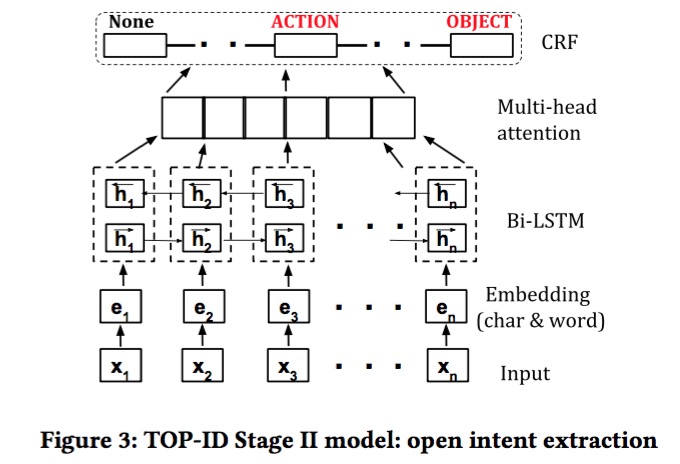
Add adversarial noise at the embedding layer.
3.3 实验

4. EMNLP-2019(AV-KMEANS): Dialog Intent Induction with Deep Multi-View Clustering.
优点:利用多视图聚类方案,考虑到上下文信息,缺点:概念描述不是很清楚,多个视图的划分策略没理由说明,且效果看起来不是很有竞争力。
推荐指数***。
code: https://github.com/asappresearch/dialog-intent-induction.
4.1 摘要
自动挖掘对话意图。聚焦于发现抽象意图,如“BookFlight”,而不关注详细意图如“departure date” and “destination”。
本文基于multi-view clustering提出一个alternating-view k-means (AV-KMEANS) for joint multi-view representation learning and clustering analysis. 其中multi-view包括query view and content view。按文章的描述理解query view 指一段对话的第一条query,content view指这段对话其余的query+answer(感觉有点牵强,文章介绍的不是很清楚)。joint multi-view representation按文章描述体现在2个view的embedding相互作用。
4.2 问题

query view不相似,但是content view(答案)很相似。
4.3 方法:定位为聚类+分类问题。
AV-KMEANS学习joint representation and multi-view cluster。 view 1 负责cluster,view 2负责classification,并且view 1的cluster assignment被用于view 2,两个view相互迭代。
1个data point / instance应该指的是dialog的1条数据。概念介绍不清楚。
4.4 实验
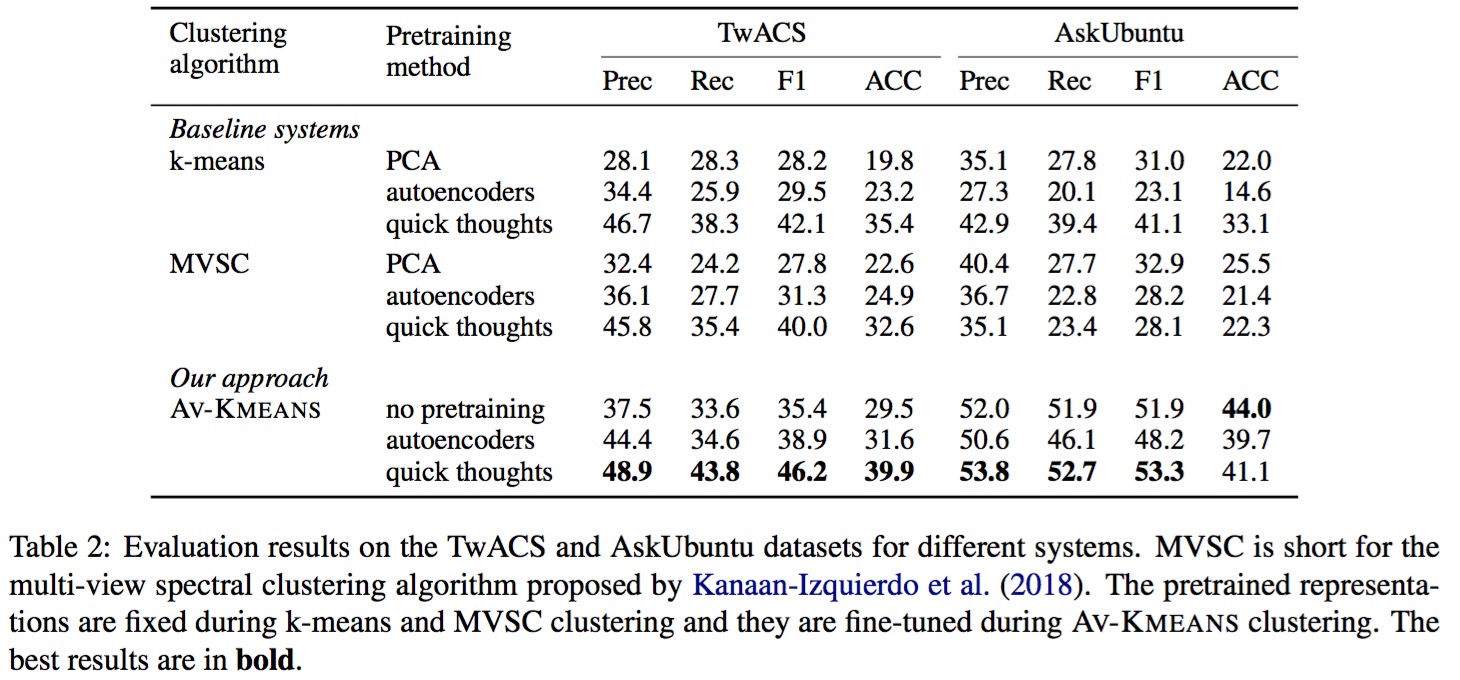
kmeans代表single-view的聚类方法,但是kmeans+quick thoughts的效果优于MVSC+quick thoughts不是很能理解,文章提到quick thoughts注入了content view的信息。
4.5 主要参考文献
1)Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning. In Neural Information Processing Systems (NIPS). 文章用此方法可以 Solely rely on the encoders to form the classifiers instead of introducing additional classification layers.
2)Lajanugen Logeswaran and Honglak Lee. 2018. An efficient framework for learning sentence representations. In Proceedings of the International Conference on Learning Representations (ICLR). 文中的quick thoughts.
5. EMNLP-2018(LSSVM): Supervised Clustering of Questions into Intents for Dialog System Applications
优点:不好说,缺点:虽然是聚类方案但需要标注数据;速度应该不快。
实验部分说明使用的模型为开源的LSSVM+实现的simlarity classifier。
推荐指数***。
data & software(in nearest future): https://ikernels-portal.disi.unitn.it/repository/intent-qa/
5.1 摘要
We developed a model for automatically clustering questions into user intents to help the design tasks. Since questions are short texts, uncovering their semantics to group them together can be very challenging. We approach the problem by using powerful semantic classifiers from question duplicate/matching research along with a novel idea of supervised clustering methods based on structured output. 主要用于辅助intent的创建过程。
5.2 方法:相似度模型+有监督聚类
1)Pairwise similarity model for short texts.
2)The superwised clustering approach builds on top of the pairwise similarity, using structured output modelling.
5.3 实验
数据:
1)Quora 相似问题对二次加工:利用传递性得到question clusters,然后重新标注 intents & slots。
2)FAQ HYPE intent corpus直接使用。
实验效果指明训练数据有点少。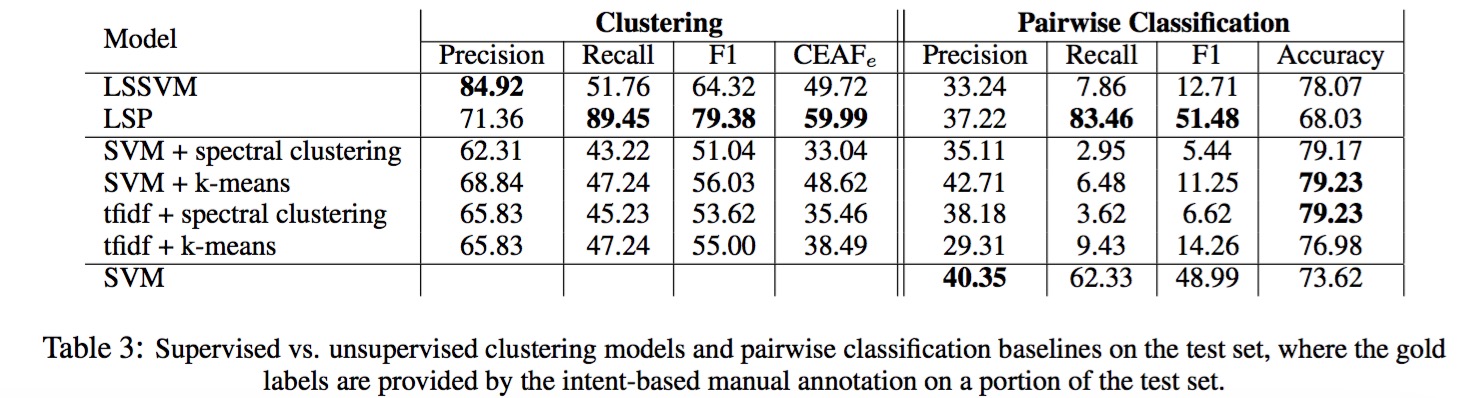
5.4 主要参考文献
1)LSSVM: http://www.cs.cornell.edu/~cnyu/papers/icml09_latentssvm.pdf
思考问题:
1)supervised clustering and classification的区别?
2)文章提到的structured out 和 supervised clustering的关系?
6. ACL-2018 Auto-Dialabel: Labeling Dialogue Data with Unsupervised
优点:无监督,模型简单直观;缺点:复杂的特征工程,从实验结果来看,主要是cluster方法起决定性作用。
推荐指数:***。
摘要&方法
构造多种上下文特征,利用无监督方法自动对对话intent和slot进行聚类。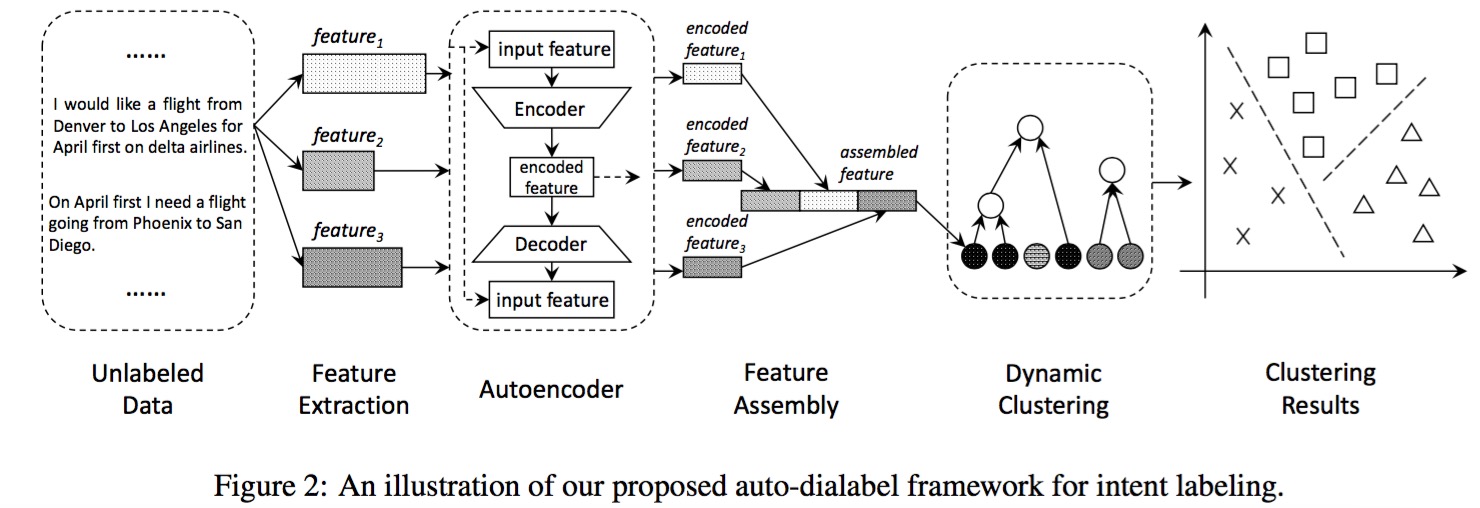
AutoEncoder:feature assemble
Hierarchical Clustering: intent cluster
总结
| model | detail | keywords | code | 推荐指数 |
|---|---|---|---|---|
| 1. LMCL+LOF (ACL-2019) | 定位为分类问题,检测一个句子属于特定intent class还是属于unknown intent。 | BiLSTM + LMCL + LOF | https://github.com/thuiar/DeepUnkID | **** |
| 2. CADC-plus (AAAI-2020) | 定位为聚类问题,利用少量的label data完成end to end的intent cluster,并且对cluster number不敏感。 | Deep Adaptive Clusterin(DAC); intent representations by BERT; pairwise-classification; Cluster Refinement with KLD loss | https://github.com/thuiar/CDAC-plus | ***** |
| 3. TOP-ID (ACM-2019) | 定位为序列标注问题,擅长输出较详细的intent | Bi-LSTM + CRF + Mulit-Head Attention + Adversarial Training | no | **** |
| 4. AV-KMEANS (EMNLP-2019) | 定位为聚类+分类问题,同3对比擅长发现抽象意图 | Multi-view Clustering | https://github.com/asappresearch/dialog-intent-induction | **** |
| 5. LSSVM (EMNLP-2018) | 相似度模型+有监督聚类 | Pairwise Similarity; Supervised Clustering | in future: https://ikernels-portal.disi.unitn.it/repository/intent-qa/ | *** |
| 6. Auto-Dialabel (ACL-2018 短文) | 定位为聚类问题,需要构造复杂的特征 | AutoEncoder; Hierarchical Clustering | no | *** |
更多详细内容待补充……